Beer and Soup
This is what it’s like to be a nerd. As a computer-geek, my friends tend to think I have a lot of “answers” about computers. In reality, I spend more time making up problems than I do solving them.
For some unknown reason I decided I wanted to extract all of the beer style data from BreweryDB and create a nice portable concept map I could use in iThoughts. As this pointless project unfolded, so did the scope. The result of a few days of work is this Python script that accepts a generic XML and outputs an OPML file suitable for import into iThoughts, MindNode or even OmniOutliner.
In theory, the important part of this experiment was learning a bit more about working with XML in Python. I learned that lxml is very powerful and poorly documented.1 I also learned that the BeautifulSoup package for Python has some handy methods for modifying XML (most of my experience with it was parsing HTML).2
Here’s the script:
:::python
#!/usr/bin/python
from bs4 import BeautifulSoup
# Start making the soup
soup = BeautifulSoup(open('/Users/weatherh/Documents/beerStyles.xml'), "lxml")
# Walk through each element in the XML by first using FindAll. Then we need to change their
# names and fix some nesting
head_tag = soup.root
for child in soup.findAll():
# Take the original name of the element and assign it to a text attribute for the OPML
child['text'] = child.name
# Change the element name to 'outline' so it's visible in the OPML as a node.
child.name = "outline"
if child.string and len(child.string) > 0:
# If an element has text, then we create a new child 'outline' element with a 'text'
# attribute containing the text. Otherwise it's not visible as a node in the concept
# map.
newChild = soup.new_tag("outline")
newChild['text'] = child.string
# Destroy the original text string
child.clear()
# add the fully formed child to the parent (like an adult adoption)
child.append(newChild)
# Need to first wrap everything in an 'OPML' tag. The new_tag function can also create an
# attribute named 'version'.
wrapper = soup.new_tag('opml', **{'version':"1.0"})
soup.outline.wrap(wrapper)
# Create a 'title' tag that is the central node of the map
newHead = soup.new_tag("title")
newHead.string = "BDB Beer Styles"
# Insert the title node before the first 'outline' node in our map
soup.outline.insert_before(newHead)
# Create a head node around the 'title' node
titleWrapper = soup.new_tag("head")
soup.title.wrap(titleWrapper)
# Slip in the body tag around the inner outline tag
bodyWrapper = soup.new_tag('body')
soup.outline.wrap(bodyWrapper)
# Write it all back to a file
xmlResult = soup.prettify("utf-8")
with open("/Users/weatherh/Documents/beerStylesUpdated.opml", "wb") as file:
file.write(xmlResult)
I think it’s reasonably well documented, even if it’s not very good Python. The resulting file can be opened directly in iThoughts.
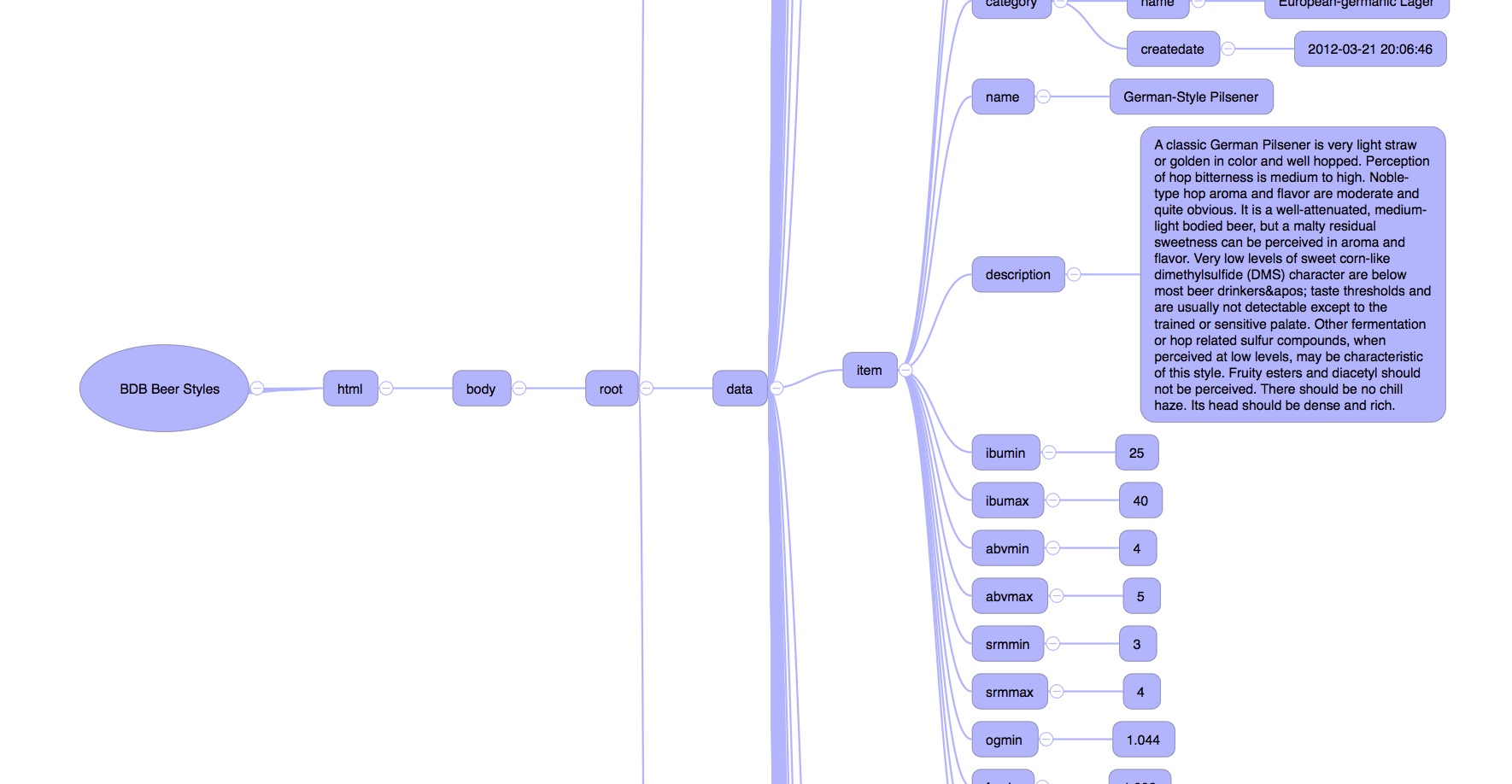
I deleted a few root nodes and applied a custom style template in iThoughts to get something rather nice looking.
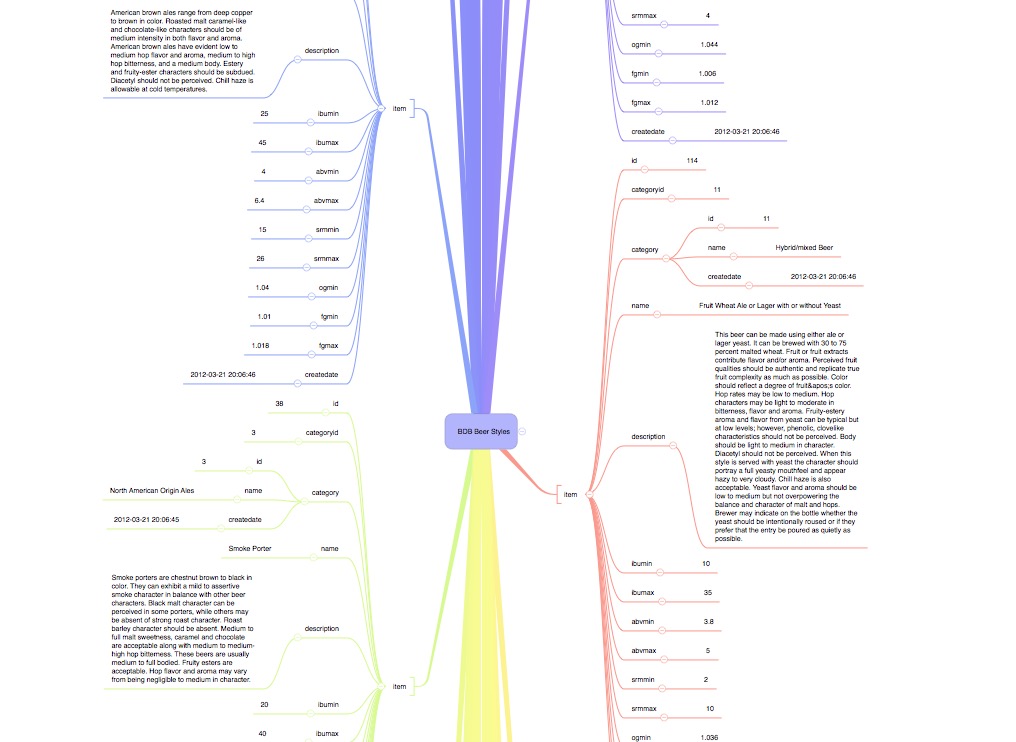
While this script was created specifically to deal with parsing the XML response from the BreweryDB API, I attempted to make it generic. It should work for most XML and should provide at least a start to converting it to OPML. I’ve tried it on the HTML source of a few webpages and it produced a concept map of the DOM. Pretty neat.
I guess I succeeded in my goal. I now have a pocket-sized concept map of beer styles.

It’s not super-useful. But, then again, this was never about the problem. It was always about the problem solving.