Fountain Characters with Editorial Sprinkling in Python
In this continuing long-weekend of Editorial posts I thought I’d share a workflow for you screenwriters out there. This workflow was inspired1 by Jonathan Poritsky, someone who knows a bit about Fountain. If you are unfamiliar with Fountain, check that link. It’s a plain text format for writing scripts and screenplays that uses a custom syntax to indicate things like scenes and character dialog.
In Fountain, character names consist of a single line in all caps following a new empty line. Jonathan wanted a workflow that would capture a characters name as a snippet so it could be easily reused after the first time it was created. I came up with this workflow to create something similar.
Designing the Workflow
I know Editorial does not have a mechanism to programmatically create new snippets. But I rationalized that a snippet might be replaced by a popup alphabetical list of characters.
The basic plan was to filter the entire current document for lines that look like a character name and then feed those to a Show List action. Tapping the item in the list would replace the selected text with the character name (or just insert it at the cursor position if nothing is selected).
Filter Lines
Editorial has an action called Filter Lines. This action takes all of the input text it receives and only passes lines that match the search pattern. It seemed trivial to filter by the Fountain RegEx for character names.
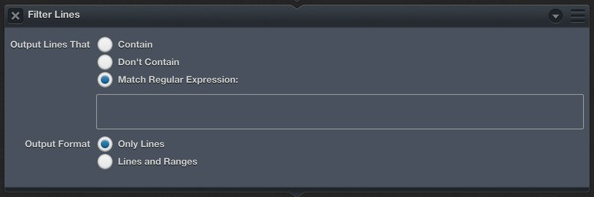
Alas, it turns out that Editorial’s Filter Lines action only recognizes the Cocoa RegEx, which I apparently suck at or is more limited than Python’s.
Excursion: Working with Filters and RegEx
When I’m developing a workflow, I pipe a lot of the output to the console. This allows me to see what’s happening between actions. Just add a bit of explanatory text and the input (or any other variable) placeholder to the Console Output action.
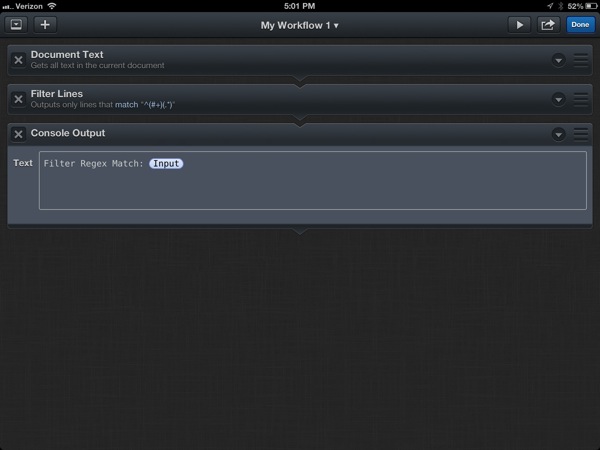
But filter actions have their own view into what they are doing that doesn’t even require console output. Tapping on the small downward triangle on the action reveals the action options. If the action has been run at least once a new button appears named “Last Output…”.
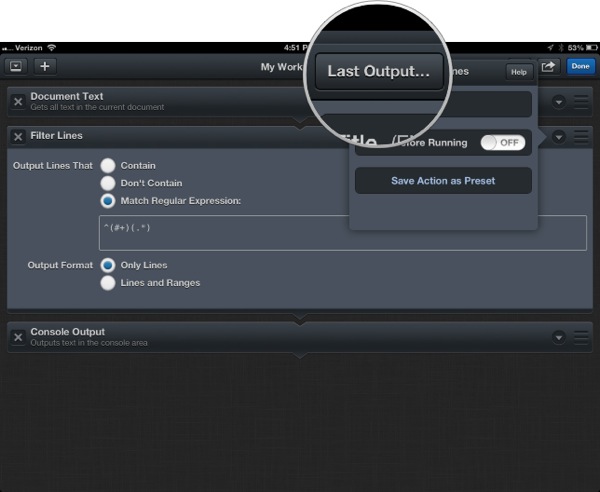
Tapping the button shows exactly what this filter added to the data stream.
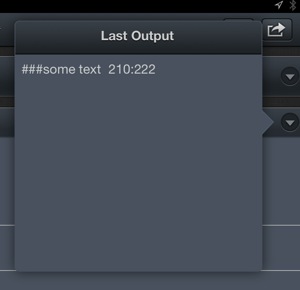
This can be a real time-saver when working with RegEx filters which can be a bit tricky in any language. Editorial does make RegEx entry a bit easier with the cheat sheet popup on the keyboard. This displays basic definitions and tapping an item inserts it into the filter field.
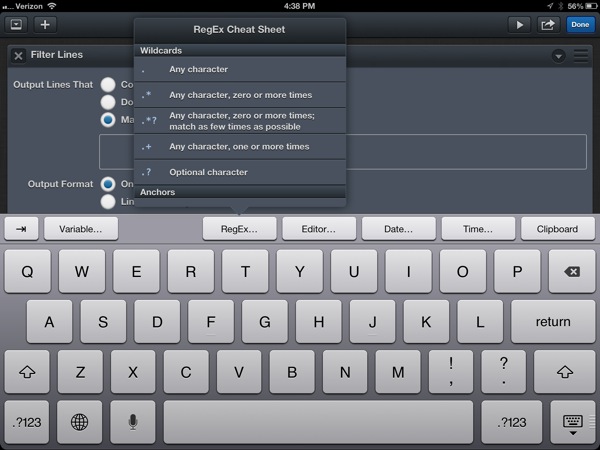
With the Filter Lines action, there are two “Output Formats”. The first option outputs just the text that matched the filter. The second option (Lines and Ranges) gives both the matching text as well as the character numbers of the match. This additional information can be useful for building more advanced document-navigation based workflows.
Just a bit of Python
If you’re ready to take the next step in creating Editorial workflows, this is a good example of when just a little bit of Python can create an entirely new tool. In this case I needed an action that could filter the incoming text for a regular expression and only pass lines that match.
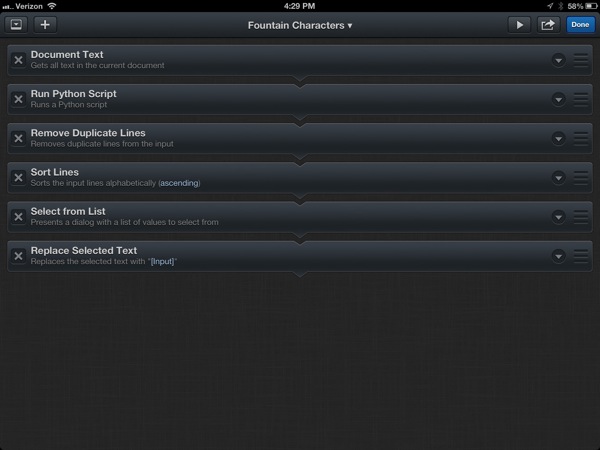
I decided my best option was to read in the content of the current text file with the Document Text action and then pass that into a Python script that could do the line filtering. Here’s the Python code that accomplishes this:
:::python
#coding: utf-8
import workflow
import re
document_in = workflow.get_input()
charac_pattern = r'(?<=\n)([ \t]*[^<>a-z\s\/\n][^<>a-z:!\n]*[^<>a-z\(!\?:,\n\.][ \t]?)\n{1}(?!\n)'
reg_obj = re.compile(charac_pattern)
matches = re.findall(reg_obj, document_in)
match_string = '\n'.join(matches)
action_out = match_string
workflow.set_output(action_out)
We need two modules to get this filter working. First, we need the Workflow module so that our script can accept incoming text and output results to the next set of actions in the workflow. document_in = workflow.get_input() receives the text produced by the Document Text action. At the end of the script workflow.set_output(action_out) passes our processed results back out of the Python action and into the Remove Duplicate Lines action.
The job of filtering our text is accomplished by using Python’s re module.2 Python supports a lot of regular expression operators. I use it way more than is healthy.
We create a regular expression string by prepending r to the quoted string, resulting in this elaborate assignment:
:::python
charac_pattern = r'(?<=\n)([ \t]*[^<>a-z\s\/\n][^<>a-z:!\n]*[^<>a-z\(!\?:,\n\.][ \t]?)\n{1}(?!\n)'
I’m not going to explain this expression because I have a life to lead outside of writing this post. It’s like explaining abstract art.
Next we compile the regular expression into a re object with reg_obj = re.compile(charac_pattern). This isn’t necessary for short scripts like this but if you have a lot of regular expression matching to do, compiling the string makes things faster. I guess I just do it “because”.
Now we can get to the business of finding all of the strings in our document that match the regular expression:
:::python
matches = re.findall(reg_obj, document_in)
Stupid-simple, right? The re.findall() method takes a few arguments. The first is the regular expression we want to match. The second is the block of text to look through. We can also add some modifier flags that change how the RegEx operators work, but that’s not necessary here.3
At this point matches contains a bunch of matched strings in a Python list object. That’s fine for Python, but kind of stinks for passing to a Editorial workflow action. To make it into some kind of meaningfull series of strings, we concatenate all of the list items separated by new lines ("\n").
:::python
match_string = '\n'.join(matches)
Now match_string contains a block of text where each line is one occurance of a Fountain character designation. We pipe that out to the rest of the workflow.
It’s a Wrap
The last few actions of the workflow just tidy up our list. The Remove Duplicate Lines does exactly what you think. So does the Sort Lines action. When it’s all done we get a relatively compact list to browse and search (created with the Select from List action).
Conclusion
Filtering text is a common operation for me. I appreciate the basic actions available in Editorial but just a few lines of Python can be the difference between giving up and making something great.
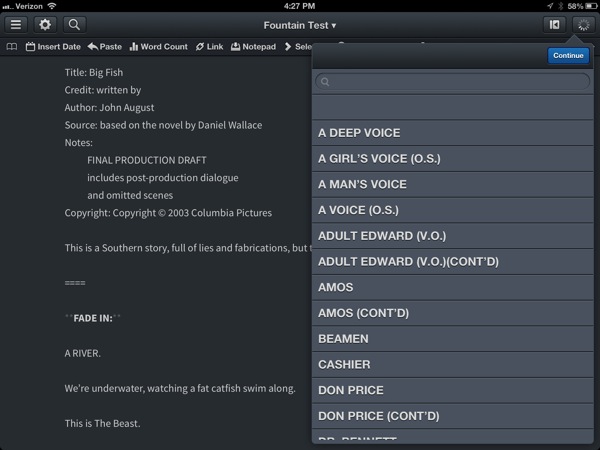
So, how’s performance of an Editorial workflow that needs to read an entire document every time it’s triggered? Well, here’s a demo using John August’s Big Fish script4, which is about 26,000 words:
-
“Demanded” or “strongly requested” may be more appropriate. ↩︎
-
I’m assuming “re” stands for Regular Expression. ↩︎
-
For example flags=re.DOTALL says that the dot operator should match all characters, including whitespace. ↩︎
-
This script is included as one of the Fountain test cases. I figured it was a good example. ↩︎