TweetFeeder Script From Twitter to RSS
Part of this record is broken: Twitter is great when you’re watching it. Interesting links come in that many people would never post to their blog. But when you’re not watching it, well, it’s just a dumb frog. I decided to fix this for myself.
What It Does
This script reads the current Twitter timeline for the people specified in the feedList parameter. The script looks for URL’s that are not images. When it finds one it posts it to a Pinboard account with a couple of tags, the original Tweet text and the original source Tweet URL.
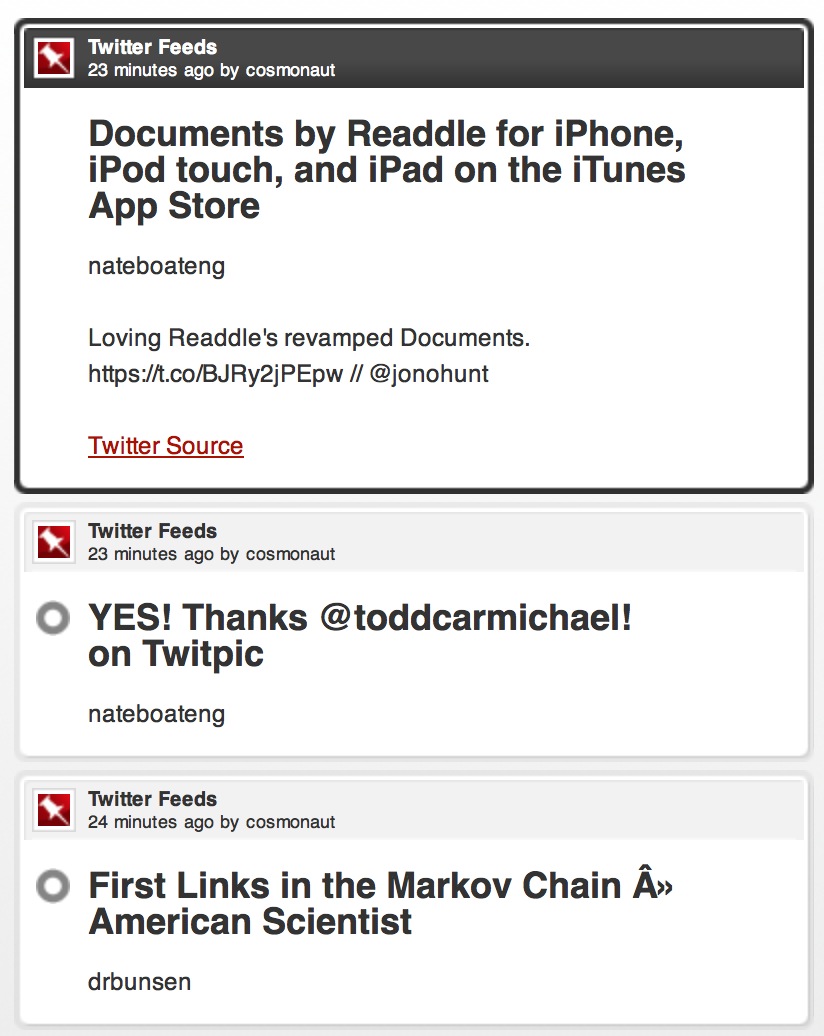
In Pinboard it looks like this:1

The tags are useful for a couple of resons. The first tag includes the Twitter user’s handle (for example: rss_jeffhunsberger). That way I can narrow down to see the links from a specific user. There’s also a main tag that groups all bookmarks added to Pinboard by this script.
The content of the bookmark is a little messy, but I’ll get to that later. The important part is that it is a proper Pinboard bookmark. The description contains all of the context I need from the Tweet and a link back to the original Tweet incase I need to reference it later.
How I Use It
Short Description: I read these links in RSS.
I have a few Pinboard accounts. I’m filthy with Pinboard. I have the main account that I use for almost everything. Then I have a dev account for playing around with the API. Finally, I have an unused account that I’ve been ignoring. This script posts to my unused account. All bookmarks are public.
Pinboard is great, but I usually just want to read an RSS feed. Guess what? That’s pretty easy with Pinboard. That’s also why I throw in some extra html tags in the bookmark description. It makes it look nicer in my feed reader.
Since each Twitter account gets its own tag in Pinboard, I can also create RSS feeds for specific users. Pinboard provides RSS feed options for any tag. That’s nice.
What You Need
You need the following things to use this script.
- A Pinboard account (duh)
- A Twitter API account with all of the secret tokens. It will feel dirty, but life is full of hard choices.
- The Python wrapper for the Pinboard API
- The Python wrapper for the Twitter API
How It Works
It’s a Python script that uses the Twitter and Pinboard libraries.
:::python
#!/usr/bin/python
import twitter
import re
import pinboard
import urllib2
from BeautifulSoup import BeautifulSoup
from StringIO import StringIO
import gzip
# The Pinboard account credentials to use
pyAccount = 'aUserAccount'
pyPass = 'anAwesomePassword'
api = twitter.Api(consumer_key='gibberish', consumer_secret='moregibberish', access_token_key='evenlongergibberish', access_token_secret='thelastbitofgibberish')
#print api.VerifyCredentials()
#Twitter users with interesting links
feedList = ['binaryghost', 'viticci', 'marksiegal', 'ttscoff', 'gromble', 'drbunsen', 'waltonjones', 'TJLuoma', 'eddie_smith', 'chewingpencils', 'jeffhunsberger', 'nateboateng']
# The adventure begins
for user in feedList:
# Get all of the user tweets
statuses = api.GetUserTimeline(user)
# Loop through all tweets and look for URLs
for status in statuses:
# A reasonably generous URL regex pattern to match
urls = re.findall('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', status.text)
# Everytime we find a URL, do some magic
if urls:
for url in urls:
# Put together the tweet info
tweetMsg = status.text
rssTag = ['rss_'+user, 'rss_tweets']
sourceURL = 'https://twitter.com/'+user+'/status/'+str(status.id)
try:
# Let's make sure the URL is valid by trying to visit it
request = urllib2.Request(url)
request.add_header('Accept-encoding', 'gzip')
response = urllib2.urlopen(request)
data = response
maintype = response.headers['Content-Type'].split(';')[0].lower()
# We don't want image links
if maintype not in ('image/png', 'image/jpeg', 'image/gif'):
# Need to handle gzip content if we want to grab the page title. Lots of sites send gzip now.
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
data = f.read()
# I guess I just prefer a real link to shitty t.co links
fullURL = response.url
if fullURL is not None:
print fullURL
# This could be done with lxml but BeautifulSoup is easy
soup = BeautifulSoup(data)
# Get the title for the page
myTitle = soup.html.head.title
pyTitle = myTitle.string
print pyTitle
# Assemble the bookmark notes. Create Twitter link for RSS viewing
bookmarkExtended = '<p>'+user+'</p>\n<p>' + tweetMsg + '</p>\n\n' + '<a href="'+sourceURL+'">Twitter Source</a>'
try:
p = pinboard.open(pyAccount, pyPass)
postResult = p.add(url=fullURL, description=pyTitle, extended=bookmarkExtended, tags= (rssTag))
except (RuntimeError, TypeError, NameError):
print RuntimeError
print NameError
print TypeError
except urllib2.HTTPError, err:
# If it's an http error like 404, just skip the link. We don't have time for this junk.
continue
I’ve commented the code where I think it helps or amuses me. I’ve also put it on Github. I’ll be refactoring it to make it a bit more flexible (and pretty) and also filter out other unwanted URL types like Instagram links. The script is pretty slow and could benefit from some more effecient code. I will not update this post. Check Github for changes.
For now, I’ve connected the script to a cron job to run every couple of hours. When run from the command line it outputs the links as they are identified. Nothing special.
Conclusion
I mostly made this as a way to exercise some muscles that have started to atrophy during a busy time at work. I miss fiddling. But now I’m pretty happy with the results. I really enjoy the new RSS feed and not missing interesting stuff from interesting people on Twitter.
-
Of course, I’m using Brett Terpstra’s Pinboard styling. ↩︎