Unpoop Twitter GIFs
Twitter seems to have an uncommon knack of not understanding how people use their service. In an effort to control more of the material published by users, they occasionally crap all over URLs and especially animated GIFs. They will convert animated GIFs to mp4 files which ruins the entire point of an animated image format.
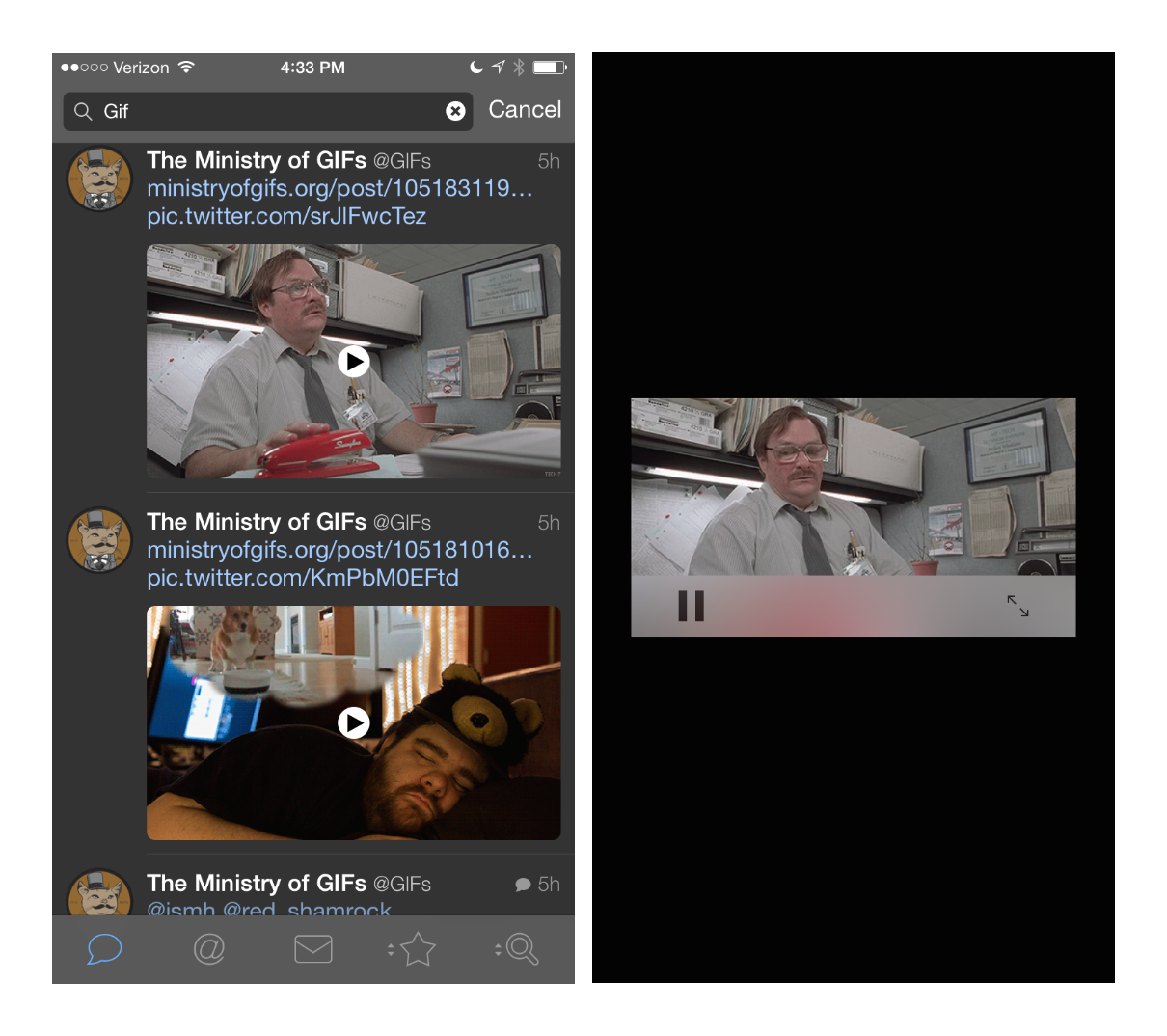
If you want to save an animated GIF that Twitter has “optimized”, it’s really a pain. So here are some scripts to unpoop Twitter-ized GIFs.
Using the wonderful BeautifulSoup for Python, this script grabs the Twitter link and tries to pull out the original link back to the source. It works with a command line argument and has almost no error handling. It’s basically pseudo-code that happens to run.
:::python
#!/usr/bin/python
import urllib
import sys
from bs4 import BeautifulSoup, SoupStrainer
poopURL = sys.argv[1]
f = urllib.urlopen(poopURL)
s = f.read()
f.close()
soup = BeautifulSoup(s, parse_only=SoupStrainer('a'))
for a in soup.findAll('a', {'class': 'twitter-timeline-link'}):
if 'twitter' not in a['data-expanded-url']:
print a['data-expanded-url']
The first thing we do is get all of the gross HTML from the orginal URL (in this case, the argument passed to the script). Once we have the HTML saved as s we can start cleaning it up.
BeautifulSoup is intended to make working with the DOM a bit more sane. It lets us parse all of the HTML looking for the bits and bobs we actually care about, regardless of how much poop gets smeared on it all. In this case, we create a soup object that contains all of the a elements from the HTML. No need to deal with anything on the page that’s not an a.
Next, we walk through all of the links in the soup object looking for any that are of class type twitter-timeline-link. From what I can tell, that’s going to contain the original link that was posted to Twitter.
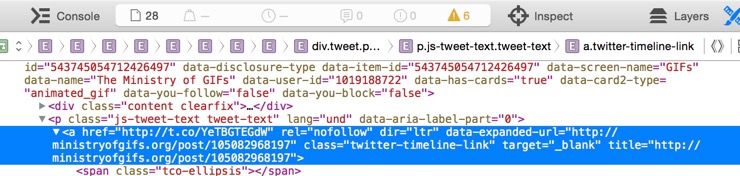
As we walk through all of the a links, we look to see if any of them contain an attribute called data-expanded-url. The original source URL will be the one not coming from Twitter. We only look at the data-expanded-url attributes that do not contain the word “twitter”. Seemed like a reasonable way to find what I was looking for and it works on everything that I’ve tried.
This is pretty portable and can be adapted for use with my favorite Mac tool, Keyboard Maestro. But I really wanted this on iOS. So here’s a Pythonista version.
:::python
import urllib
import clipboard
from bs4 import BeautifulSoup, SoupStrainer
poopURL = clipboard.get()
f = urllib.urlopen(poopURL)
s = f.read()
f.close()
soup = BeautifulSoup(s, parse_only=SoupStrainer('a'))
for a in soup.findAll('a', {'class': 'twitter-timeline-link'}):
if 'twitter' not in a['data-expanded-url']:
cleanURL = a['data-expanded-url']
clipboard.set(cleanURL)
This Pythonista script does the same thing but operates on the clipboard. Copy a poop-i-fied Twitter link and run the script to get the original source URL on the clipboard.
Now let’s deal with the situation where the original source link points back to another landing page. I don’t mind animated GIFs posted to sites like GIFY but I usually just want to quickly, save the original image file. This Pythonista script looks for a GIF anywhere on the page and returns the URL
:::python
import urllib
import clipboard
from bs4 import BeautifulSoup, SoupStrainer
import re
clipURL = clipboard.get()
f = urllib.urlopen(clipURL)
s = f.read()
f.close()
soup = BeautifulSoup(s, parse_only=SoupStrainer('a'))
for a in soup.findAll('img'):
if re.match(r"(?:([^:/?#]+):)?(?://([^/?#]*))?([^?#]*\.(?:gif))(?:\?([^#]*))?(?:#(.*))?", a['src']):
print a['src']
Pass in a URL like this: http://ministryofgifs.org/post/105086890812
And get back a URL that looks like this: http://giant.gfycat.com/ShimmeringHappygoluckyAmurstarfish.gif.
{kind=link}
That’s quick.
There’s not a great increase in complexity with this script except for what it’s looking for. First, it filters out anything that’s not an a link, just like the previous atrocity. Next, it finds and then traverses all of the img elements on the page. As it passes each img it checks to see if there’s a src attribute and if the value for the attribute looks like a link to a GIF. That’s what the regular expression I stole does.
There are a lot of edge cases that I’m not handling, for example, what if there are multiple GIFs on the same page. That’s why it’s printing the URLs out to the console instead of setting the clipboad. This is just a start but I need to consider value for the investment. This handles most of what I need.