Matching MultiMarkdown Meta Data with Hazel

Hazel 3 brings the ability to create custom matching rules using AppleScript or Shell Scripts. This seemingly subtle addition takes Hazel to an entirely new level. I've just begun tinkering with this and already I've developed some rules that seem almost magical.
MMD Meta Data
MultiMarkdown supports meta data headers in text. These are arbitrary header lines in the file that begin at line 1 and end at the first empty line. The meta data category ends with a colon and is followed by the value. The meta data can be anything but there are some commonly accepted standards. Upon conversion of the MMD file, the meta fields are stripped out. However, they can first be accessed by the MultiMarkdown tools.
Just check out Fletcher Penny's guide.
:::text
title: This is my title
date: 04/02/2012
category: markdown
tags: @blog
@markdown
@hazel
In the example above, I'm using the standard meta fields "title", "date", and "category". I've also added my own custom field called "tags". Each tag goes on a single line. Additional tags follow on subsequent lines with at least one level of indentation.
The Python Markdown Module
I've written about this module before. I'm not going to rehash all of it, but this is a very good Python tool for accessing the MMD meta data.
The Hazel Rule
I've created the following rule in Hazel to move files to my Note Archive when the "@archive" tag is added to the MMD meta data field.
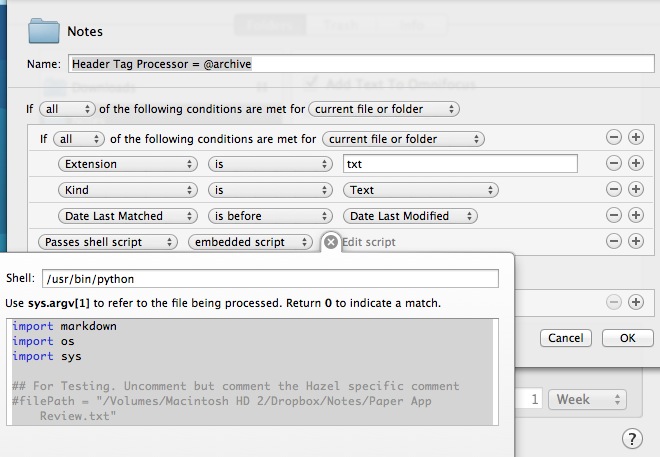
Note that this is a shell script that runs a Python script. The Shell path parameter needs to point to the path for Python.
Here's the Python script that does the matching magic. As usual, this should not be used to operate heavy machinery. It's ugly and poorly written. There's way too many IF statements. I just wrote this over the weekend and put it into use today. I'm sure it's full of bad style and ticking time bombs.
:::python
import markdown
import os
import sys
## For Hazel. Received the file path from the rule execution.
filePath = sys.argv[1]
## The tag to look for
matchTag = "@archive"
try:
myFile = open(filePath, "r")
rawText = myFile.read()
myFile.close()
fileName = os.path.basename(filePath)
# Start off using the file name as the post title
title = os.path.splitext(fileName)[0]
# Handle the odd characters. Just kill them.
rawText = rawText.decode('utf-8')
# Process with MD Extras and meta data support
md = markdown.Markdown(extensions = ['extra', 'meta'])
# Get the html text
html = md.convert(rawText)
## extract the tags but keep them as a list
if md.Meta:
if 'tags' in md.Meta:
headerTags = md.Meta['tags']
if matchTag in headerTags:
#print matchTag
## Tag was not found. Returning "0" will indicate a pass, anything else will indicate a fail.
sys.exit(0)
else:
sys.exit(1)
else:
sys.exit(1)
else:
sys.exit(1)
## This is bad form, but if there is no Markdown meta field, just return a failed match.
except AttributeError:
sys.exit(1)
except Exception, e:
sys.exit(1)
About the Script
This rule is hard coded to match on the MMD "tags" meta data field matching the tag "@archive". The script received the file path from Hazel. It then reads all of the text and extracts the MMD meta fields if they exist.
For this script to be of any use to Hazel, it needs to exit properly. It took me awhile (and an email to Hazel support) to figure this out. A successful match should exit the Python script with sys.exit(0). Anything else will tell hazel that it did not match. If the exit statement is omitted the it will likely count as a positive match.
I've tried to exit without matching where ever possible. I don't want the rule to get stuck. If it doesn't work, I'll know it.
WARNING
Be aware, creating inefficient scripts with poor error handling can bring Hazel to its knees. I know. That entire Python script will be executed with every file in the directory that Hazel is running it against. I would not add much complexity or processing to a condition script.
Handle with care. Pun intended, and very bad.
Efficient Matching
I've tweaked the matching rules a bit to make it more efficient. I don't need every file run through the Python script. I only want the newly changed files to make it that far, so I've added the nested "If all" conditions.
I don't fully understand the Hazel matching engine, but this gives me the fastest processing. It will only run newly modified text files through the Python script. On a directory of over 500 text files, this Hazel rule executes in about a second. Without those extra rules, it can take almost a minute.
What's the Point?
I think this is quite powerful. I'm using plain text as if it was file meta data. I'm doing away with Hazel rules that rely on OpenMeta tags for text files. I think this is a better alternative.
MMD meta data can really be anything. I could have meta data with a file path to direct the file. I could have additional processing commands for the markdown conversion.
The rule involves a bit of code, which is counter to some of the reasons to use Hazel (no code scripting). This example is a basic shell that could be used to match on other MMD meta data fields and values.